type
status
date
slug
summary
tags
category
icon
password
真值生成
参考SurroundOcc:利用多帧激光雷达点云,以及3D目标检测标签和点云语义分割标签,生成稠密的OCC真值。
多帧点云拼接
在3D检测框内的为动态物体,其他为静态场景。(还可以结合3D检测前后帧的坐标区分动静态)
对于静态场景,根据每一帧的位姿信息直接将各帧点云拼接起来。
- 转换到统一的参考坐标系(第一帧的LiDAR坐标系),拼接后转化放置到目标帧的坐标系
- 也可以用融合建图算法,效果更好
对于动态物体,收集并拼接其在所有帧中的点,创建更密集的对象表示。(nuscenes数据集中自带目标ID,如果没有ID需要做目标跟踪)
- 以3D bbox坐标和朝向角为参考,拼接时转换到以物体为中心的局部坐标系
- 拼接后的物体点云重新放置到目标帧的正确位置
体素化和语义标签
泊松重建稠密化点云。
将点云体素化。
基于稀疏的点云语义标签,使用最近邻方法为所有的体素分配语义标签。
改进
Occ3D:用2D语义分割结果优化voxel噪声和类别;增加对相机遮挡区域的标注。
OpenOccpancy:模型生成伪标签,人工去除错误标签,迭代优化标注和模型。
目标有拖影如何优化?
不同方案
基于BEV特征
FlashOcc:利用通道到高度变换将扁平化的 BEV 特征重塑为三维体素级别占用 logits。
基于3D体素特征
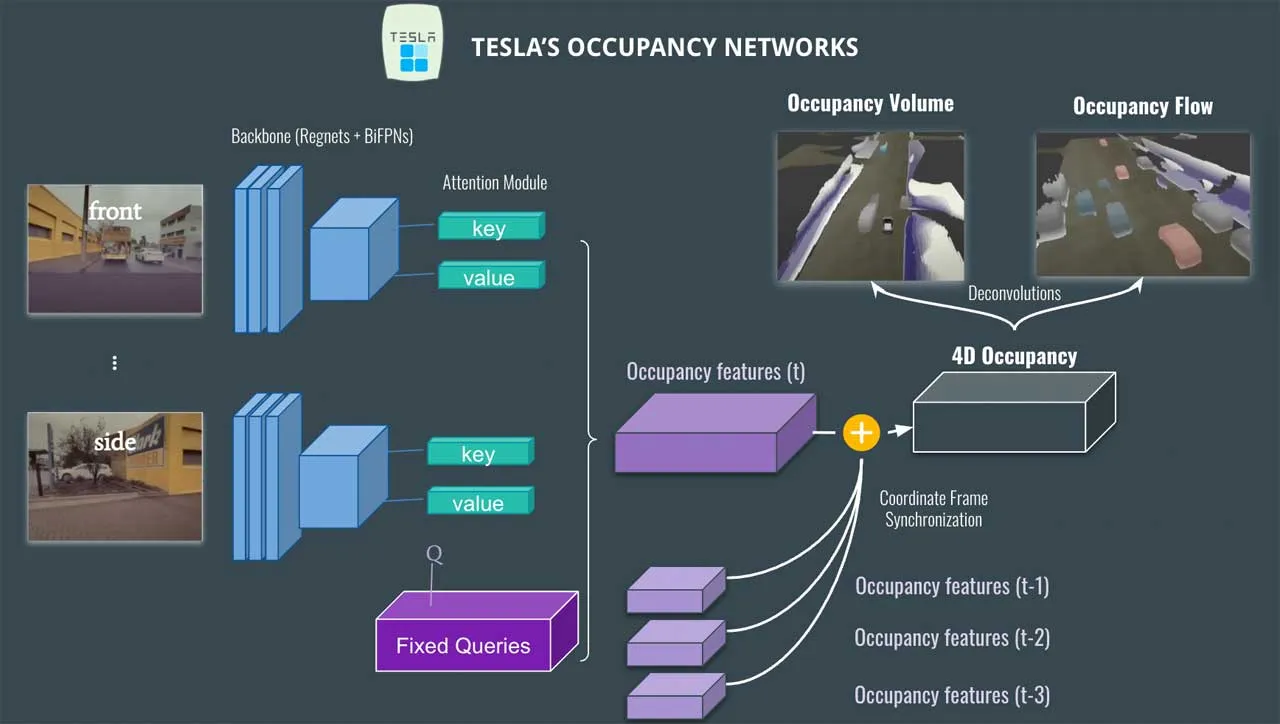
图像输入:SurroundOcc
点云输入:OpenOccupancy
基于三视图特征
图像输入:TPVFormer
点云输入:PointOcc
基于Transformer查询
SparseOcc:SparseBEV + Mask2Former + 一些细节上的改变
Sparse Voxel Decoder 预测稀疏无类别的 3D occ 结果。用稀疏体素解码器以从粗到细的方式重建场景的稀疏几何形状。这仅对非自由区域进行建模,显着节省了计算成本。(每层用预测头估计体素的占用分数,丢弃掉分数低的体素)
Mask transformer decoder 预测稀疏 3D 空间中的语义[B, Q, C]和实例[B, Q, C]特征。
实例特征[B, Q, C]与 Sparse Voxel Decoder 输出的体素特征[B, N, C]做点积,形状[B, Q, N],表示每个查询对每个体素的响应强度。
semseg = torch.einsum("bqc,bqn->bcn", mask_cls, mask_pred)
mask_cls[b,q,c]表示查询q认为存在类别c的置信度
mask_pred[b,q,n]表示查询q认为体素n被占用的强度
- 对于每个批次b、每个类别c、每个体素n
- 计算所有查询q的加权求和:
sum_q(mask_cls[b,q,c] * mask_pred[b,q,n])
- 结果形状为
[B, C, N],表示体素n属于类别c的综合分数
- 对类别维度取最大值,得到每个体素的最优类别
模型推理返回
'sem_pred': [B, N],告诉我们这些被占用的体素属于什么语义类别
'occ_loc': [B, N, 3]},告诉我们哪些体素位置被占用
参考:
weiyithu/SurroundOcc: [ICCV 2023] SurroundOcc: Multi-camera 3D Occupancy Prediction for Autonomous Driving nuScenes SOTA!SurroundOcc:面向自动驾驶的纯视觉3D占据预测网络(清华&天大)-CSDN博客 一览Occ与自动驾驶的前世今生!首篇综述全面汇总特征增强/量产部署/高效标注三大主题...-CSDN博客 [ECCV 2024] SparseOcc 纯稀疏3D占用网络和 RayIoU 评估指标 - 知乎 SparseOcc纯稀疏占用网络论文笔记(南大/上海AI LAB) - 知乎
- 作者:Chenastron
- 链接:http://chenastron.xyz/article/23548e05-8beb-8051-bbc8-e4bc5cdbbea2
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。