type
status
date
slug
summary
tags
category
icon
password
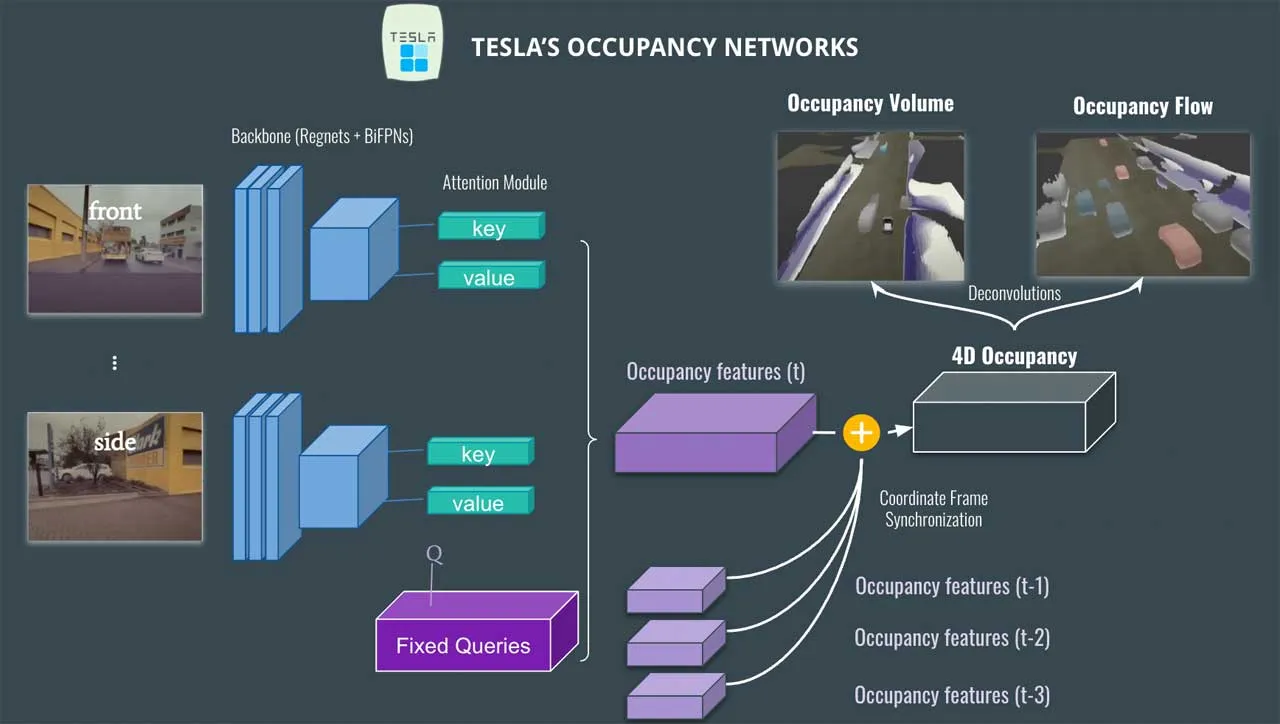
BEV 感知的四类视图转换模块方案:
- IPM的平坦地面假设过于严格,因此通常只用于车道检测或自由空间估计。
- Lift-Splat使用额外的网络估计深度,耗费大量显存,且限制其它模块大小,影响整体性能。
- MLP 的收益平衡点需要考虑数据量、GPU资源和工程工作。罕见。
- Transformers 的数据依赖性使其更具表现力,但也难以训练。另外,在量产自动驾驶汽车资源有限的嵌入式系统中部署 Transformer 也可能是一个重大挑战。
LSS 系列
LSS
图像特征结合深度估计,生成3D视锥点云。深度概率分布与语义特征逐像素计算外积,形成带权重的3D表示。
通过相机内外参数,将多视角点云统一投影到以车辆为中心的BEV网格。
LSS 具体 pipeline
- CreateFrustum():根据配置参数构建单个相机的视锥(Frustum)
- 在每个图像特征点位置(高H、宽W)扩展D个深度,最终输出是DxHxWx3,其中3表示坐标[h, w, d]
- GetGeometry():利用相机内外参,对N个相机Frustum进行坐标变换,输出视锥点云在自车周围物理空间的位置索引
- CamEncode():对原始图像进行逐个图像特征点地进行深度和语义的预测,输出视锥点云特征
- 首先原始图像过EfficientNet得到特征
- 然后过一层卷积直接得到D+C通道数的特征,D属于深度分布,C是语义特征
- 对D维深度做softmax归一化
- 将D与C做外积,最终输出的是HxWxDxC;BxN张图像,对应的输出就是BxNxHxWxDxC
- VoxelPooling():将上述GetGeometry()和CamEncode()的输出作为输入,根据视锥点云在ego周围空间的位置索引,把点云特征分配到BEV pillar中,然后对同一个pillar中的点云特征进行sum-pooling处理,输出B,C,X,Y的BEV特征
- 首先将点云特征reshape成MxC,其中M=BxNxDxHxW
- 然后将GetGeometry()输出的空间点云转换到体素坐标下,得到对应的体素坐标。并通过范围参数过滤掉无用的点
- 将体素坐标展平,reshape成一维的向量,然后对体素坐标中B、X、Y、Z的位置索引编码,然后对位置进行argsort,这样就把属于相同BEV pillar的体素放在相邻位置,得到点云在体素中的索引
- 然后对每个体素中的点云特征进行sumpooling,代码中使用了cumsum_trick,巧妙地运用前缀和以及上述argsort的索引;输出是去重之后的Voxel特征,BxCxZxXxY
- 最后使用unbind将Z维度切片,然后cat到C的维度上。代码中Z维度为1,实际效果就是去掉了Z维度,输出为BxCxXxY的BEV特征图。
缺点:深度估计不准,通过任务head中的loss难以学习优化;外积操作导致计算量和参数量大。
BEVDet
BEVDet是LSS在3D检测上的工程应用落地。
- 改进或区别在于:
- 怎么做3D目标检测任务
- 对不同的类别分别设置了不同的检测头,这些检测头的参数并不共享,在检测头前有一个共享卷积层提取特征
- 每个类别的检测头检测的内容都是一样的:沿着x,y轴方向的偏移量(reg分支);z轴也就是预测物体的高度信息(height分支);物体的尺寸大小信息(长-宽-高)(dim分支);物体偏航角的正、余弦(rot分支);物体沿x,y轴方向的速度(vel分支);分类置信度(heatmap分支)
- 改进目标检测任务的NMS操作,使其更适应3D目标检测
- 自适应的放大不同类别的检测框大小,让检测框可以适应2D的NMS算法
- 在BEV空间进行数据增强
- 加速视图变换
- 通过CUDA利用GPU的并行资源完成加速
- 更强的主干网络和更优的BEV编码器
BEVDet 后来扩展为 BEVDet4D,通过整合前一帧的特征来引入时间维度,不仅能更准确地输出3D包围盒,还能直接、可靠地估计物体的速度。
BEVDepth
BEVDepth 使用编码的相机参数向量,通过 MLP 和 SE 层调制深度和上下文特征,实现相机感知的深度估计。引入了显式的深度监督训练,可以获取更准确的深度估计。
- 相机参数向量包括:
- 内参矩阵(intrins):相机的焦距和主点坐标
- IDA变换矩阵(ida):图像数据增强变换
- 传感器到自车坐标系变换(sensor2ego):相机外参信息
- BDA变换矩阵(bda):鸟瞰图数据增强变换
如果输入包含 lidar 数据,还有一个深度细化模块,使其能够细化那些位置不正确的特征。因为用不着,还未深究。
还提出了一种“快速视角转换操作”,以解决使用估计深度将特征从图像视图投影到BEV时的速度瓶颈。似乎是利用了cuda的多线程,暂时不研究。
BEVFormer 系列
基于 Transformer 的模型难以工程落地,延迟高,训练成本高,部署复杂,仅作了解。
虽然从图像生成BEV实际上是一个ill-posed问题,如果先生成BEV,再利用BEV进行检测容易产生复合错误。但是我们仍然坚持生成一个显式的BEV特征,原因是因为一个显式的BEV特征非常适合用来融合时序信息或者来自其他模态的特征,并且能够同时支撑更多的感知任务。
前向推理过程:
- 在 t 时刻, 输入车上多个视角相机的图像到 backbone, 输出各图像的多尺度特征 (multi-scale features) : ,其中 是第i个视角相机的 feature, 是多个相机视角的总数。同时, 还要保留 t-1 时刻的 BEV Features 。
- 在每个 BEVFormer Encoder layer 中, 首先用 BEV Queries Q 通过 TSA 模块从 中查询并融合时域信息 (the temporal information), 得到修正后的 BEV Queries ;
- 然后在同一个 BEVFormer Encoder layer 中, 对 TSA “修正”过的 BEV Queries , 通过 SCA 模块从 multi-camera features 查询并融合空域信息 (spatial information), 得到进一步修正的 BEV Queries 。
- 这一层 encoder layer 把经过两次修正的 BEV features (也可以叫做BEV Queries)进行 FF 计算, 然后输出, 作为下一个 encoder layer 的输入。
- 如此堆叠 6 层, 即经过 6 轮微调, t 时刻的统一 BEV features 就生成了。
- 最后, 以 BEV Features 作为输入, 3D detection head 和 map segmentation head 预测感知结果, 例如 3D bounding boxes 和 semantic map。
通过SCA模块的密集查询构建BEV特征图,通过可学习的采样偏移和注意力权重来查询最相关的图像特征点。
可变形注意力,通过一个小型网络预测出少量采样点的偏移量。这些偏移量会告诉模型,应该从参考点的哪个相对位置去采样特征作为键和值。这些采样点通常不在规整的网格上,需要通过双线性插值来获取这些位置的精确特征。只在这少数几个采样点上进行注意力计算。
- BEVFormer 的改进
- FB-BEV 结合了类似LSS的前向投影(将图像特征投影到3D体素空间,考虑深度不确定性)和类似BEVFormer的后向投影(优化稀疏的3D表示,整合更强的语义先验)的优点。
- SparseBEV 摒弃了构建密集BEV特征的传统方法,转而采用“完全稀疏查询机制” 。它使用可学习的查询柱和自适应注意力,选择性地提取和处理最相关的特征,从而实现高效的纯摄像头3D检测。
- 与DETR3D相比的改进:尺度自适应的自注意力模块;自适应性的时空采样模块以实现稀疏采样的自适应性,并充分利用长时序的优势;使用动态 Mixing 来自适应地 decode 采到的特征。
BEVFusion
BEVFusion的框架非常直观,照相机和激光点云数据经过各自的encoder进行特征编码后,camera特征采用LSS的自底向上的方法进行bev视角转换,lidar特征用voxelnet或pointpillar处理得到,再将二者特征拼接后输入BEV encoder进行BEV特征编码,即得到融合后的BEV特征,来支持下游多任务。
M2BEV/Fast-BEV
LSS学习预测一组离散深度分布,用深度概率给予相机射线上不同深度的voxel不同的特征权重。
M2BEV的主要区别在于假设相机射线上每个voxel的权重都是一致的,图像特征直接投影到不同深度的voxel上,从而提高计算效率、减少内存占用。
- Fast-BEV在M2BEV的基础上整合了多种技术(有些可能M2BEV中已有,不细究):
- 优化视图转换:优化的部署友好视图变换以加速推理
- 预先计算固定的投影索引并将其存储为静态查询表
- 让所有相机的特征投影到同一个的BEV特征图上,避免再做多个BEV特征图的体素聚合
- 高效BEV编码:使用了非常少的残差块作为基础BEV编码器,因为实验表明增加block数对性能提升不大。对3D检测任务来说,增加BEV网格的分辨率并不能提升性能。使用了三种降维操作来加速编码器,分别是“空间到通道”(S2C)、多尺度拼接融合(MSCF)和多帧拼接融合(MFCF),避免使用占用大量内存和计算量的3D卷积算子,具体的:将shape为H * W * Z * C的BEV特征转换成H * W * (Z*C)的形式,即shape-to-channel操作;将不同的分辨率的BEV特征在channel维度进行concat,完成多尺度拼接融合,即MSCF;同样的操作也在时间融合时使用,即MFCF。
- 多尺度特征融合:由于特征视角转换速度快,因此在进行2D特征提取时采用FPN的方式输出3种分辨率的特征;3个特征分别通过LUT查表的方式完成视角转换,形成3个不同分辨率的BEV特征,通过上采样的方式完成分辨率对齐。
- 时间融合:融合当前帧BEV特征和存储的历史帧特征作为输入,参考了BEVDet4D和BEVFormer
- 使用三个历史关键帧采样当前帧,其中每个关键帧的间隔为0.5秒
- 采用了BEVDet4D中的多帧特征对齐方法,获得四个对齐的BEV特征后,直接连接起来并馈送到3D编码器中
- 数据增强:在图像和BEV空间上增加了强烈的3D增强,例如随机翻转,旋转等,参考了BEVDet
- 图像增强:在图像上应用数据增强,同时更改相机内参矩阵
- BEV增强:增强变换同时应用于BEV特征图和GT,通过修改相机外参矩阵来控制
参考:
- 作者:Chenastron
- 链接:http://chenastron.xyz/article/21848e05-8beb-8070-93b2-d9d34752d608
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。